Functions: The details
Environmental Data Analysis and Visualization
Get to know tidy evaluation
Why do we get an error?

Get to know tidy evaluation
Why do we get an error?
When function arguments indirectly refer to the name of a column, R takes it literally.
Plot functions
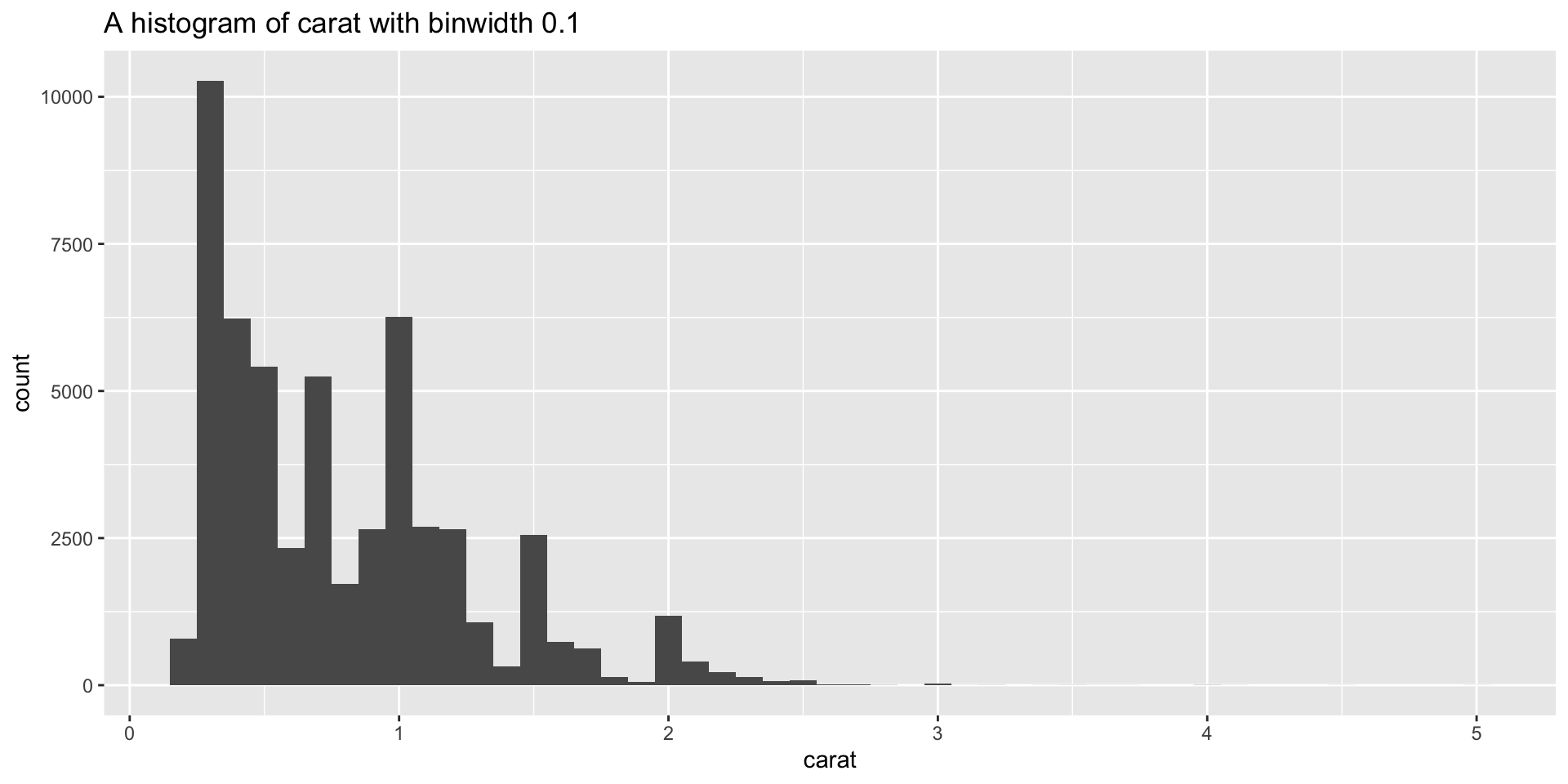
Want: I need to make a lot of histograms with different binwidths.
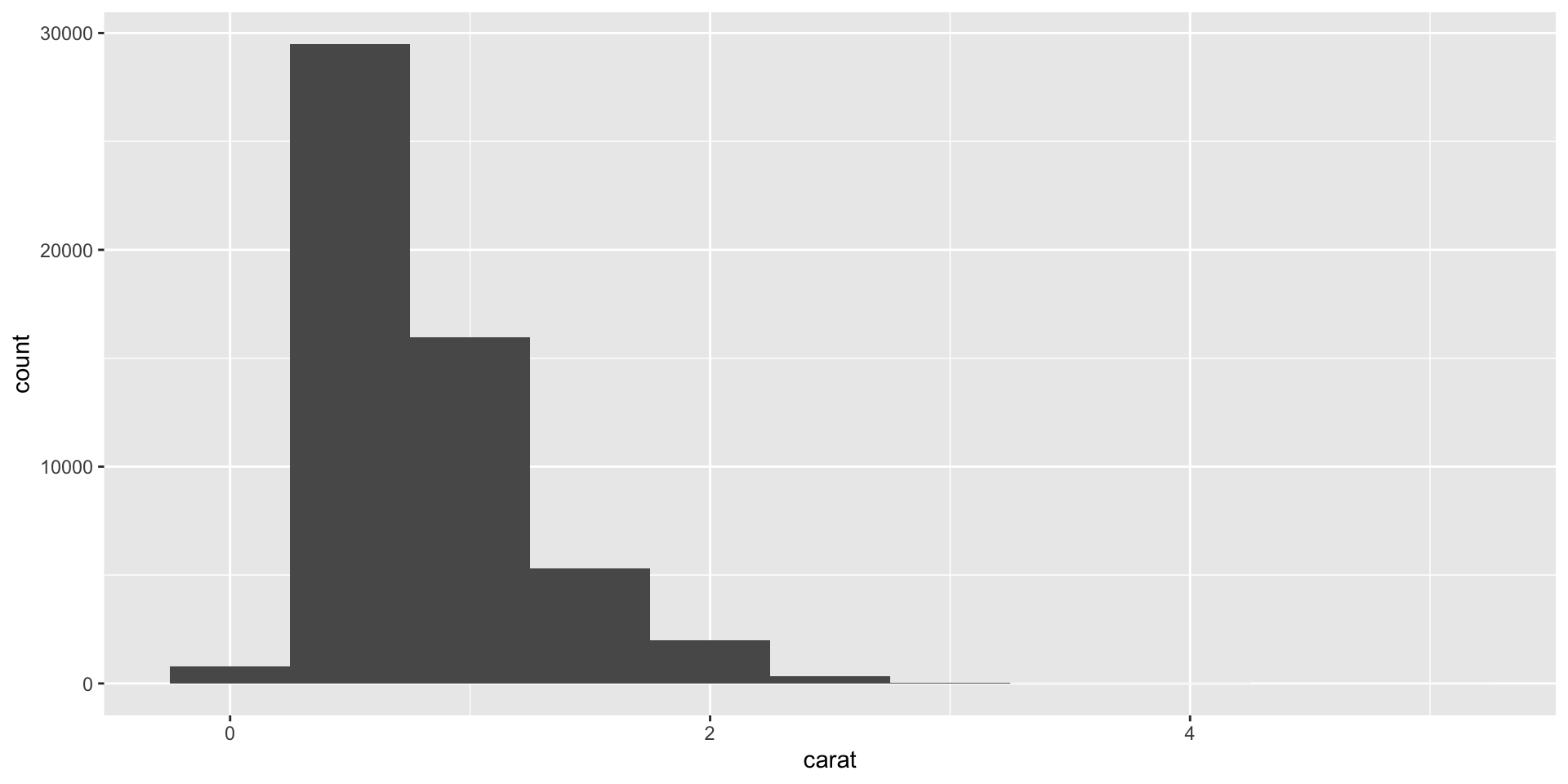
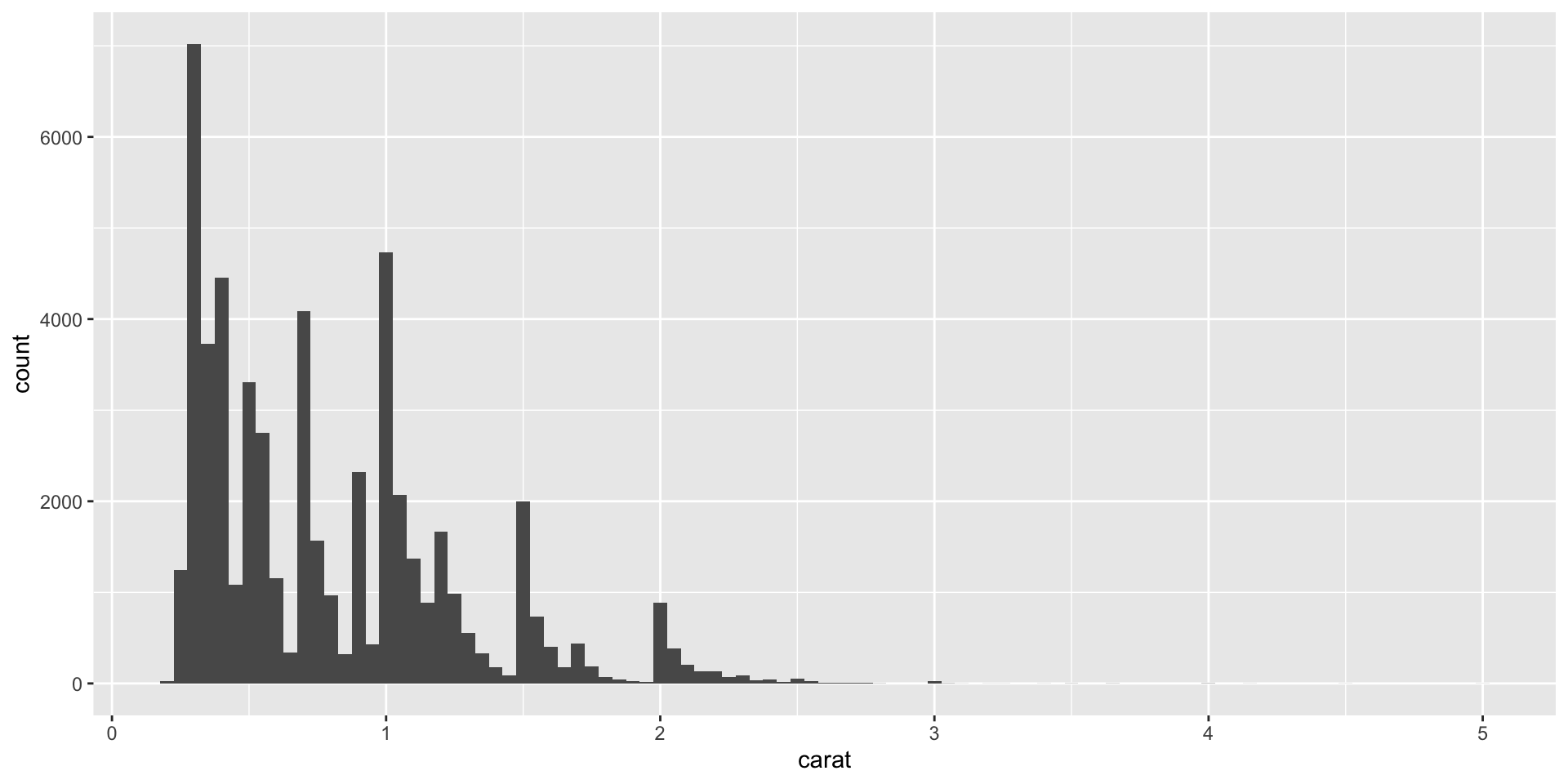
Make a plot function
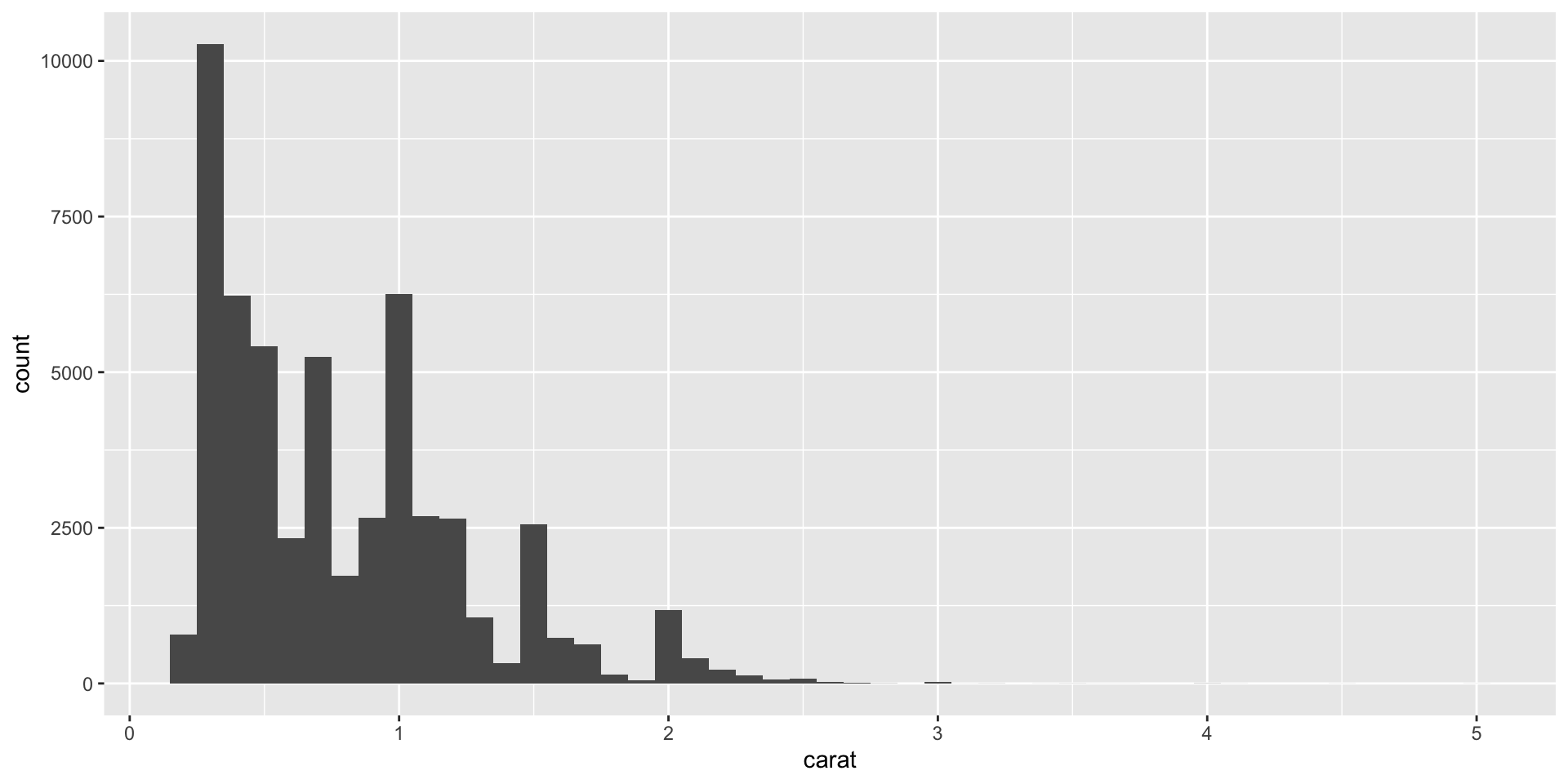
Optional: Add components after running plot function
Our histogram() function returns a ggplot2 plot, meaning you can still add additional components if you want. Just remember to switch from |> to +:
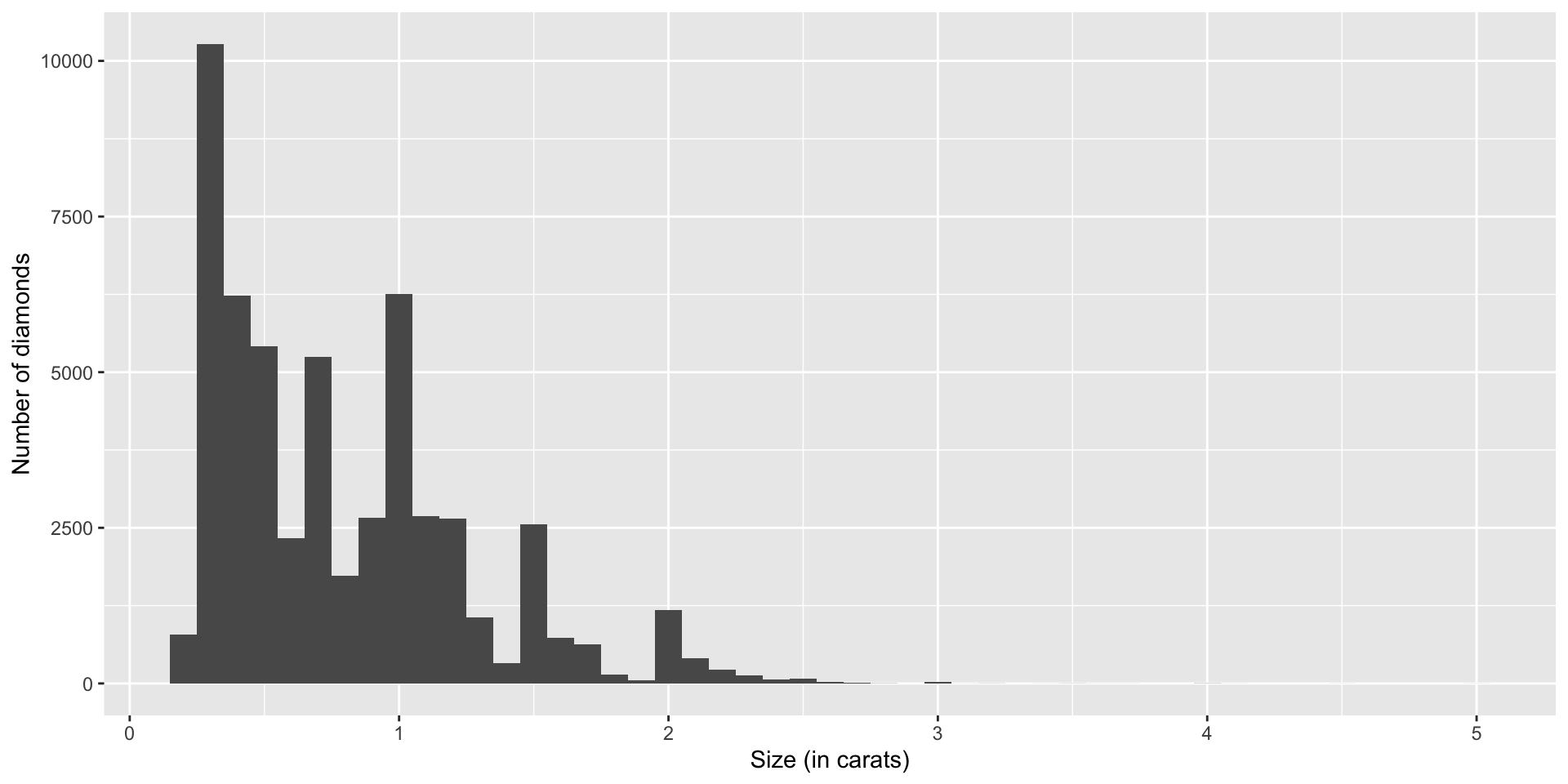
Plot function with more variables
Function to eyeball whether or not a dataset is linear by overlaying a smooth line and a straight line:
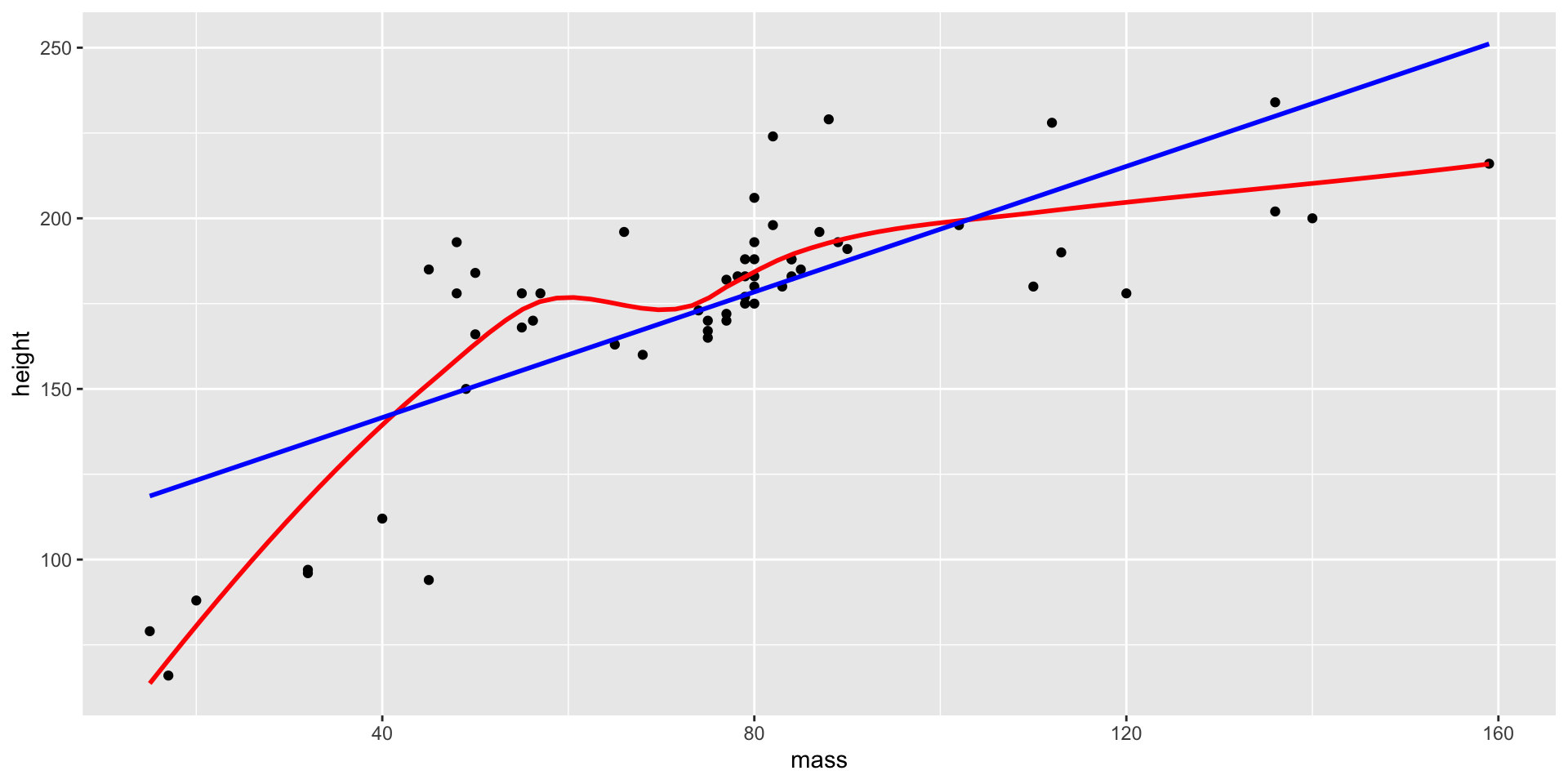
Make a function to wrangle then plot
Use the fct_infreq() function to sort factor levels according to frequency, then plot in a horizontal bar chart:
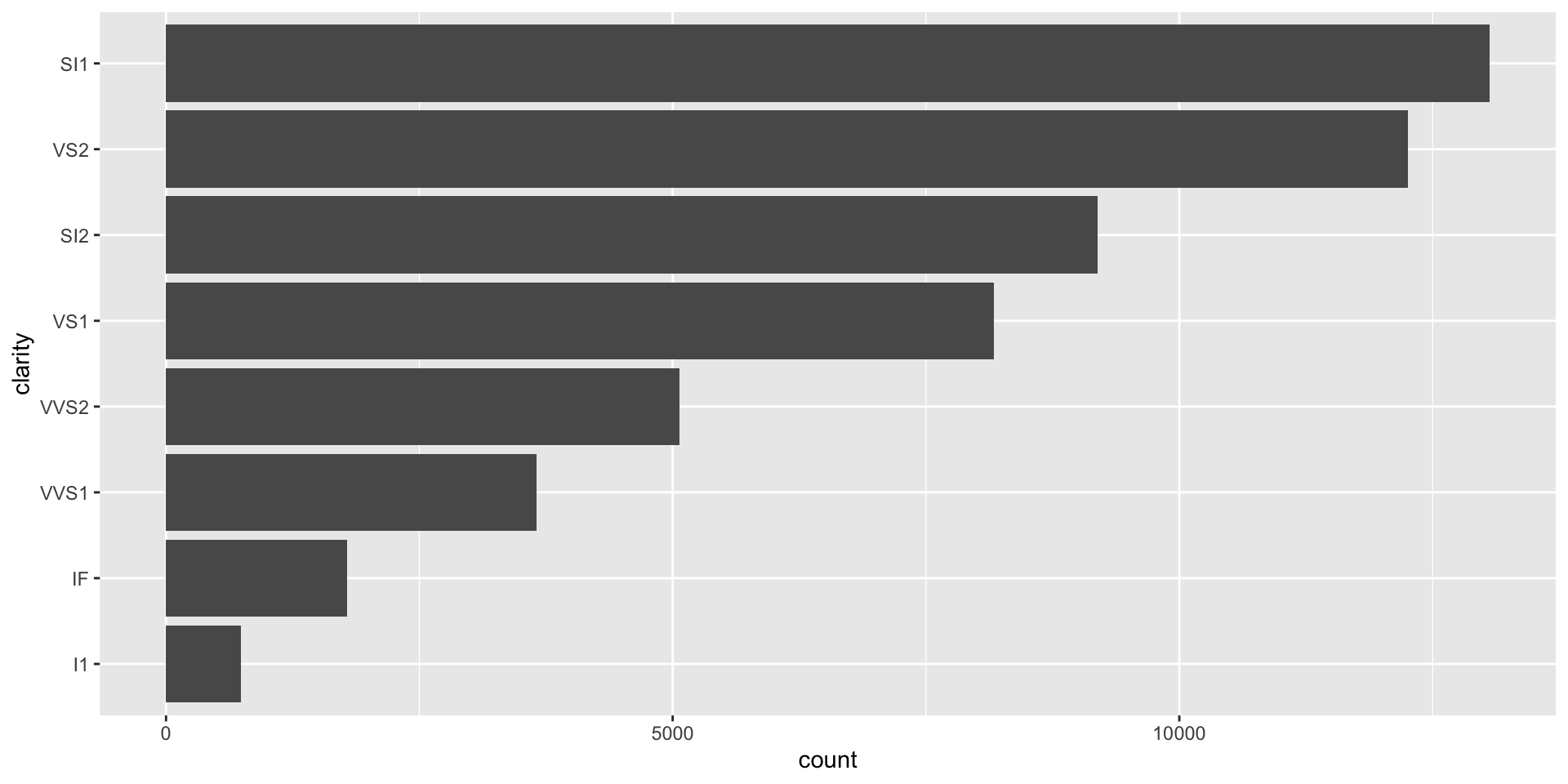
Label plots in a function based on user inputs
Add a plot title that labels the variable and binwidth: